UML和模式应用
AUP: Agile Unified Process
敏捷统一过程, 轻量级的 RUP.
本书通过两个案例 <NextGen POS> 和 <MonopolyGame> 将 AUP 贯穿起来. 从 OOA/D 的概念到系统架构中模式的应用, 一层一层的展开, 介绍了如何从最初的软件需求, 结合 UML 帮助软件开发、设计人员更好地进行领域模型的表达和建立, 以及随着迭代的进行, 逐步细化设计, 最终完成一个有弹性、易维护、可扩展、封装变化的软件系统.
这么多内容导致的结果就是都不够深入, 但也起到一个非常好的知识点梳理作用.
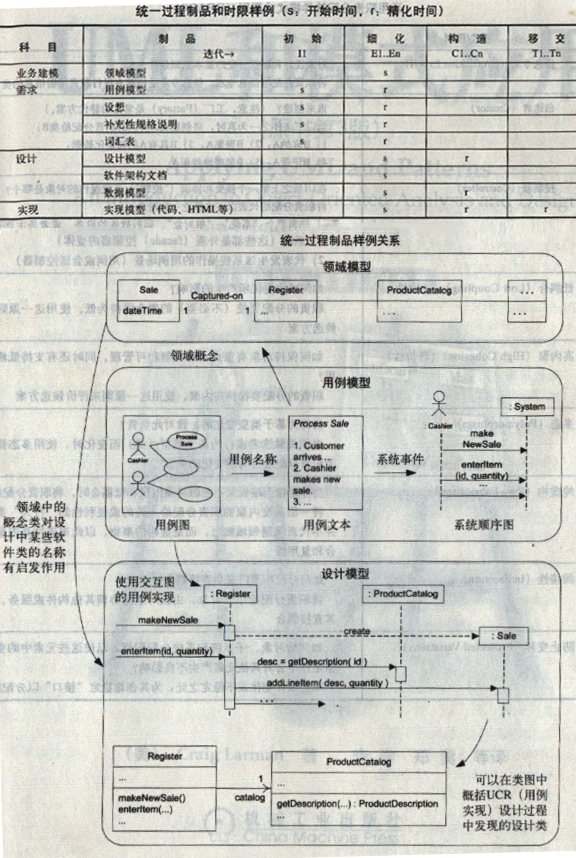
注意: 所有制品都是可选的. 我们应遵循敏捷建模的原则, 只对具有创造性、最困难的部分进行建模, 其目的是为理解和沟通, 而不是文档本身.
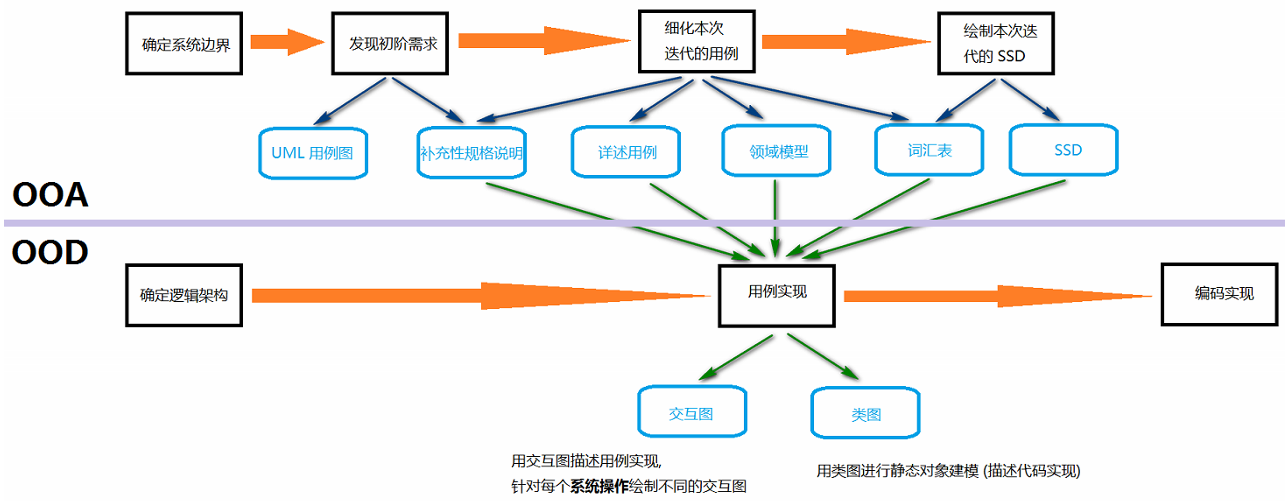
OOD 阶段的主要输入/输出我总结如下:
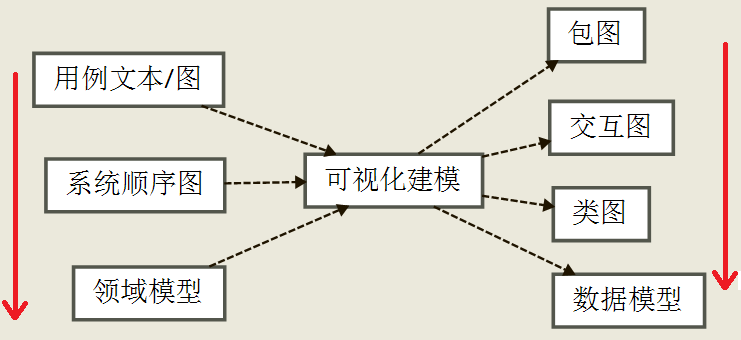
因为是迭代式开发, 所以 OOA 虽然是 OOD 的输入, 但是反过来, OOD 也会促进 OOA 更加成熟. 这是个螺旋式增量精化的过程.
系统顺序图描述了详述用例文本中用户对软件系统的入口操作 (称之为系统操作), 通常由控制器接收这些操作 (控制器是 GRASP 中的一种模式, 后面介绍 GRASP 时再详述, 这里把系统当成一个整体就行了, 系统操作描述的就是用户如何使用系统.)
OOD 阶段的关键目标就是用例实现: 描述某个用例基于协作对象如何在设计模型中实现, 通常用交互图来描述; 用例实现通常以场景为单位, 因此也称为场景实现.(P233)
我的理解就是 OOD 所做的大部分工作就是为了实现用例中的场景. 为什么只是大部分? 因为还有部分工作是为了实现补充性规格说明中的非功能性需求.
因为软件世界是对现实世界的抽象, 所以领域模型指出了需要设计的软件对象, 根据低表示差异, 领域模型通常能启发软件对象的名称及其属性.
反过来, 设计工作中通常也可能会发现一些在早期领域分析中遗漏的”新”概念, 如果这些”新”概念是有价值的, 会在将来被作为后续设计工作的输入 (通常都是这种情况), 那么应该更新我们的领域模型.
设计工作还会虚构出一些软件类, 这些软件类的名称的目的可能会与领域模型完全无关 (通常是为了实践 GRASP 的纯虚构及间接性, 后面再具体详述).
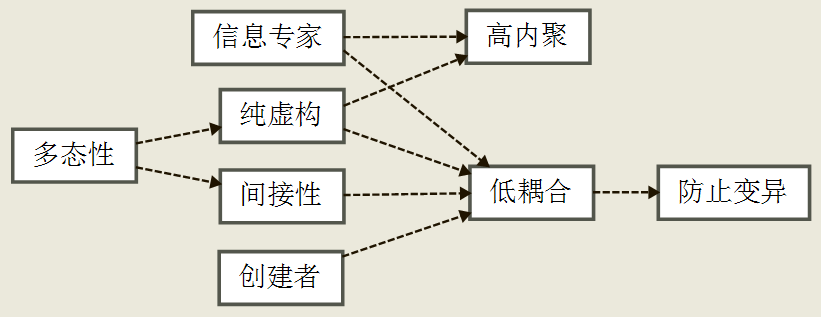
GRASP
GRASP 定义了 9 个基本的 OO 设计原则/模式, 根据我的理解, 将他们划分成两大类: 应用性模式 和 指导性原则. 如下图所示.
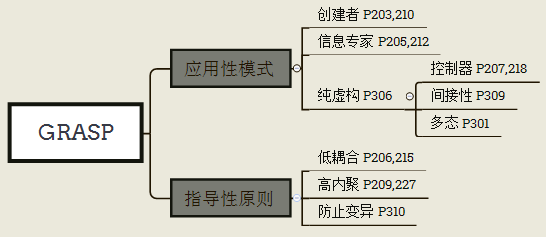
应用性模式包含了 6 种软件设计的职责分配方案, 而 3 种指导性原则是对方案的评估.
另外要阐明一点, 耦合本身并不是问题, 有问题的是对不稳定因素之间的高耦合 (P217,466), 所谓不稳定因素包含: 变化点 和 进化点 (P314).
通常, 变化点可以在用例详细分析时产生的架构因素中识别出来, 如 POS 系统需要支持多个第三个税金计算器接口、系统需要在数据库不可用时访问本地缓存等;
而进化点则没那么好分析, 过度的进行远景/未来验证, 这种精力花费并不值得, 我所采用的做法是设计时假定进化不存在, 而当变化真正到来时, 通过重构去完善我的设计, 本书也表明, 对进化点的预防性工程成本要高于对简单设计重做的成本 (P314).
低耦合
what?
元素与其它元素之间的连接、感知及依赖程序的度量.
耦合本身并不是问题, 有问题的是对不稳定元素进行耦合, 没有绝对的度量标准来衡量耦合程度的高低, 重要的是估测当前耦合程度, 并估计增加耦合是否会导致问题.
另一种极端情况就是耦合过低, 或者压根就没有耦合, 要知道, 系统是由相互连接的对象构成, 对象之间通过消息通信;
如果一个类的耦合过低, 那么说明这个类单独完成了所有职责, 那么就要考虑这些职责是不是相关联的, 也就是高内聚. (这个问题真的见到很多人犯. 定一个超大的类, 然后把所有的职责都给它来完成…)
why?
当两个元素耦合, 一个发生变化, 则另一个也会受到影响.
因此, 构建软件最重要的目标之一就是如何降低依赖性, 减少变化带来的影响, 提高重用性.
较低的耦合往往能够减少修改软件所需的时间、工作量和缺陷.
高耦合的问题:
高耦合会依赖于其它许多类, 当其中任一发生变化,
本体也就可能发生变化
单独地看本体会难以理解, 需要连带依赖的类一起看
还是因为过度依赖其它类, 导致本体很难重用
how?
创建者、信息专家、多态性、间接性、纯虚构,
这些模式指导我们做出支持低耦合的选择.
高内聚
what?
度量软件元素操作在功能上的相关程度,
也用于度量软件元素完成的工作量.
根据经验, 高内聚的类的方法数目较少、功能性有较强的关联, 而且不需要做太多的工作.
why?
不良的内聚 (低内聚) 对象包含众多不同的职责领域,
不仅意味着对象仅依靠本身工作,
而且任何依赖这个低内聚对象的其它对象还会趋于产生不良耦合
(高耦合). 为什么呢? 因为低内聚对象将其它对象的职责”抢”过来了,
那么本来其它对象能自己完成的职责就需要跟这个低内聚对象进行耦合才能完成…所以不良内聚和不良耦合通常是相关的.
因此, 高内聚保持对象是有重点的、可理解的、可管理的, 并且能够支持低耦合.
高内聚不止适用在类上, 还适用在方法上, 每个方法应该有其清晰和单独的目标, 并将一组相关的方法置于一个类中, 如果一个方法有超出一个以上的动机而被迫修改, 就靠仔细考虑考虑了.
一个方法应该只做一件事, 应该短小 、短小、再短小, 更准确地说是每个方法应该是只做抽象概念上的一件事, 而只做一件事的方法是无法把逻辑分段的.
要确保方法只做一件事, 方法中的语句就要在同一抽象层级上. 不同的抽象层级是有个自上而下的逻辑关系的, 即”then”的关系, 也就是说, 需要在每个函数后面跟着下一抽象层级的函数: 方法 A: (为了做 A 我需要先做 B) 调用 方法 B 方法 B: (为了做 B 我要先做 C, D) 调用方法 C, 方法 D
例如有 else 或者 case 判断, 那么可能会有问题, 因为它们不是 then 关系, 而且违反开放关闭原则.
如下是一个重构的例子:

低内聚的问题:
- 难以理解 - 难以复用 - 难以维护 - 易受变化影响
how?
信息专家、纯虚构, 这些模式指导我们做出支持高内聚的选择.
因此可以用一个简单的方法来衡量: 如果一个类的属性被类中的每个方法所使用, 则该类具有最大内聚性.
高内聚对应的就是单一职责原则, 这是最简单同时也是最难做到的原则~ 说法很简单: 如果能想到多于一个的动机去改变一个类, 那么这个类就具有多于一个职责, 就应该考虑类的职责分离. 但其实要做到真正的职责单一是件很难的事 (信息专家可以一定程序的保证这点).
防止变异
what?
如何设计对象、子系统和系统,
使其内部的变化或不稳定性不会对其它元素产生不良影响.
防止变异其实是个更底层、更通用、更基本的原则. 几乎所有的模式/原则都是防止变异的特例.
如下图所示:
除了基于上面这些 GRASP 模式/原则外, GOF 中提到的里氏替换原则及迪米特法则也是防止变异有效手段.
里氏替换是个种很简单的思想, 用来指导我们接口/父类的设计, 这种思想指出, 针对父类/接口类型的引用 T, 传递任何一个 T 的实现/子类引用 S, 程序都应该”按照预期”进行工作.
迪米特法则 (LOD: law of demeter), 又叫得墨忒耳律, 也叫最小知识原则, 还有一个更简单的定义: 只与直接的朋友通信 (不要和陌生人说话).
对于一个对象, 其直接朋友包括以下几类:
- 以参数形式传入到当前对象方法中的对象
- 当前对象的成员对象
- 如果当前对象的成员对象是一个集合, 那么集合中的元素也都是朋友
- 当前对象方法的返回值
- 当前对象创建出来的对象 (注意, 从当前对象的朋友那获取到的对象不是直接朋友)
非以上 5 类的对象最好不要作为局部变量的形式出现在当前对象的内部.
PS, Clean Code 6.4 章指出, 这里的对象都指的是有行为职责的类, 那些只有属性 (可以有 getter 方法) 的类应该被当作 “数据结构” 来看待, 而不是类. “数据结构” 是不需要遵守 Lod 的, 因为对数据结构而言, 没有行为就没有通信 (getter 方法不能算行为).
Lod 还有个前提原则: 如果一个方法放在本类中, 即不增加类间的关系, 也对本类不产生负面影响就放在本类中.
如以下例子:

打叉的语句依赖于实际中 Sale 对象与 Payment 对象的连接, 这种设计是不稳定的, 因为你不能保证 Sale 对象与 Payment 对象的连接长期有效. 而且这种设计让 Register 与 Payment 耦合.
该例只是遍历了一层路径, 通常程序遍历的路径越长, 也就越脆弱.
要遵循这一原则, 上述代码就需要在直接朋友 (Sale) 中添加新的职责, 让它来获取 Payment 提供的信息, 并且对 Register 隐藏了 Payment 的细节:
Money amount = slae.getThenderedAmountOfPayment()
有一点很重要, 并不总是需要对此进行设计,
应该只对易变或不稳定的元素进行设计,
过度的设计会让系统变得很零碎, 反而不易理解和维护,
如果我们把精力放到”远景/未来验证”或没有实际理由的设计上,
这种精力花费并不得当.
这就涉及到设计中的两个变更点:
- 变化点: 现有、当前系统或需要中的变化, 例如系统必须支持多个税金计算器接口.
- 进化点: 预测将来可能会产生的变化点, 但并不存在于现有需求中.
理论上, 对变化点和进化点都应进行设计, 然而除非是显然易见的进化点, 否则没有必要去花费精力”猜测”是否存在进化点, 对进化点的预防性工程成本要高于对简单设计重做的成本 (P314).
在我们最初编程时, 假设进化不会发生, 而当进化真的到来时, 我们就应用设计以隔离以后发生的同种类进化.
对于应用程序中的每个部分都刻意地进行抽象不是一个好注意, 拒绝不成熟的抽象和抽象本身一样重要.
信息专家
what?
某个类有完成一个职责所需要的信息,
那这个类就是该职责的信息专家, 可以把该职责安置到这个类中;
最基本的职责分配原则之一, 可以一定程度的保证单一职责原则;
除非是控制器或创建者问题, 否则信息专家模式应该是首先要考虑的模式 (P241);
信息专家对于认知职责和行为职责都适用, 是给对象分配职责的基本原则, 或者说信息专家指导我们如何给对象分配其职责.
How?
把职责分配给具有完成该职责所需信息的那个类. 反过来说也一样,
即对象应该只完成与其所具有信息相关的职责.
因此, 分配职责的第一步就是搞清楚 “完成这个职责需要哪个信息?”, 实际应用中有两种情况:
- 如果在当前设计模型中存在相关的类, 则首先查看设计模型.
- 否则查看领域模型, 并尝试根据低表示差异映射成设计模型.
信息专家其实描述了一个很基本的主题: 把职责和需要的数据放在一起. 信息专家能指导我们做出支持高内聚的设计, 如果一个类的属性被类中的每个方法所使用, 则该类具有最大内聚性.
根据信息专家可能会产生多个候选者, 此时需要根据指导性原则 (低耦合、高内聚、防止变异) 对候选者进行评估.
实践
在绘制交互图时, 应考虑并决定职责, 然后在类图的方法分栏中总结.
在分配职责时会产生一种”直觉”, 即软件对象的职责通常能描述现实对象的动作. 如果根据信息专家得到的职责违反了这种”直觉”, 也就是说给对象分配了现实领域中它本身不应负责的职责, 就会降低对象的内聚. 通常我们使用纯虚构解决这个问题.
创建者
what?
谁创建了某个类的新实例?
How?
创建一个类的实例, 这也是一种职责 (创建职责),
因此创建者模式可以说是信息专家模式的特化,
专指如何分配创建职责.
它在信息专家模式的基础上新添了几项优先级更高的原则:
- 包含或组成聚集 A
- 记录 A
- 直接使用 A
- 具有 A 的初始化数据 (信息专家, 通常是”描述类” P109)
优先级从上往下是递减, 如应优先考虑有包含或组成聚集关系的对象.
那么, 为什么会有比信息专家优先级更高的原则呢?
因为创建者的本质是寻找在任何情况下都与被创建者具有”连接”的对象. 这么做的目的是为了支持低耦合, 因为这两个类之间已经是可见的了, 即存在已有的关联, 因为用它来做为创建者不会增加设计的耦合度.
如信息专家模式一样, 通常:
- 如果在当前设计模型中存在相关的类, 则首先查看设计模型.
- 否则查看领域模型, 并尝试根据低表示差异映射成设计模型.
如果一个类是稳定的, 不容易变化的, 那么创建者模式应该是我们的首选, 如果是不稳定元素, 我们应该把创建职责委派给 GOF 中的工厂模式.
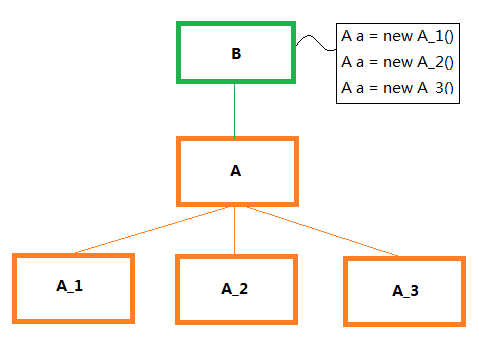
例如, 如下结构, 虽然对 A 使用了多态, 但是对使用者 B 而言,
它还是需要知道 A_1、A_2、A_3 的存在, 而且如果新增了 A_4, 那 B
又得增加 A a = new A_4() 的代码,
显然这种设计不是我们想要的, 因此可以使用工厂模式对其 A
进行封装.
控制器
控制器的针对性非常强.
控制器模式体现模型-视图分离原则 (P153 这里的模型指的是领域层对象, 而不是 MVC 中的 Model), 防止 UI 层与过多的领域层对象发生耦合, 同时也避免在 UI 层混入应用逻辑 (简单的来说, 就是 UI 层拿到数据后就可以直接用了), 这样做的好处是当你想更换一种 UI 时, 你无需在新的 UI 中重写应用逻辑.
补充一点, 模型-视图分离原则除了指导我们避免在 UI 层混入应用逻辑外, 还指导我们领域层不应向上耦合 UI 层 (P415). 那么就会涉及如何刷新 UI 的方案? 有两份种解决方案:
- 通过 UI 层轮询, 通常适用于 Web UI
- 基于观察者模式, 通常适用于 GUI
简单的说控制器完成两个任务:
- 接收 UI 层发送的系统操作
- 处理系统的应用逻辑 (注意, 不要内聚领域层的职责)
- 对数据流进行封装、转换
控制器可以是真实领域对象, 也可以是纯虚构对象. 这取决于你要处理的系统操作有多少;
如果系统操作相对来说比较少, 并且职责基本都是相关的, 那么可以让代表”整个系统”、”根对象”、”设备”或”子系统”的领域对象来充当控制器, 简单的来说, 就相当于”系统”的外观; 通常来说, 都会有一个领域对象代表”整个系统”, 如 GameSystem、POSSystem, 这些是较好的选择.
否则, 虚构一个代表用例的控制器是首要选择,
通常被称作用例或会话控制器 (以下统一称为用例控制器),
<UseCaseName>Handler 或者
<UseCaseName>Session 是对它的有效命名方法,
同一用例场景下的所有系统操作应使用相同的控制器.
用例控制器维护与同一个用例相关的工作流, 如对数据流进行封装、转换, 还可以维护关于用例状态的信息 (例如 Session), 如果你的系统有完善的异常处理机制, 通常异常也应从底层向上抛出到控制器中处理;
当存在多个用例控制器时, 会将这些控制器归纳到一起形成应用层.
注意要避免控制器的职责过多, 把本应是领域层对象的职责也给分配给控制器是不对的, 这会形成臃肿控制器 (这种现象在 MVC 及其它三层模型变体中很常见, 因为它们是贫血模型, 那么必然会造成 Controller 层的臃肿 ).
再补充一些我个人对 MVC 的理解, 我并不是排斥 MVC, 而是排斥贫血模型, MVC 体现的只是一种分层解耦、关注分离的设计思想, 这是可取的; 我有时依然会使用 MVC, 但是我会在 Controller 与 Model 之间再封装个 Domain 层 (也就是领域层), 而对 Model 的定义是 Domain 与数据库交互传输的数据结构 (struct), 不把它理解为通常的对象, 因为它不能包含对象的职责 (严格意义上这已经不是 MVC 了).
多态
应该只对不稳定元素进行设计, 而不是过度的设计.
多态主要解决用来消除代码中基于类型的选择, 实现可插拔的软件构件.
如果使用 if - else 或
switch 语句来设计基于类型的判断,
那么当出现新的类型时, 则需要修改这段逻辑判断块.
多态即是用来解决这个问题的, 说白了就是封装变化.
使用多态后, 通常会提供一个工厂函数中, 由这个函数去生成对应类型的抽象类, 以此消除外部类对多态子类的依赖.
一些语言中, 可以使用反射彻底消除变化,
而另一些语言, 却依然要在工厂函数中去使用
if - else 或 switch.
间接性
为了避免和易变、复杂的事物直接耦合而虚构出一个中介对象来隔离风险, 这个一个中介对象来将易变、复杂的事物封装起来提供一个统一的接口, 外部只与这个接口发生耦合, 避免与多个对象耦合.
GOF 的适配器、外观、中介都是间接性模式.
编程中的多数问题, 都可以通过增加一层间接性来解决, 如果有, 那就多加几层.
纯虚构
实践中, 应少考虑, 尽量用函数式编程.
软件设计中, 一部分类来自领域模型的解析, 还一部分是基于相关的行为或算法而组织到一起虚构出来的概念, 例如帮助类、领域驱动中的领域服务类等等, 这些在领域中找不到概念, 是虚构出来的类, 所以叫纯虚构.